セルフホストできるスライド共有サイトをつくった
はじめに
SlideShareが2021年9月にScribd傘下となり、スライドをPDFとしてダウンロードする機能が有料となったことがアナウンスされています。
Bringing the SlideShare and Scribd communities together - Scribd Blog
さらに先日、スライドの閲覧にも上限が設けられたことが話題となりました。下図のように、有料サブスクリプションを案内するバナーやポップアップが表示されます(2022年6月現在)。

https://www.slideshare.net/Slideshare/slideshare-is-joining-scribd-237760779
筆者は、これまでの登壇資料はSlideShareではなくSpeaker Deckに投稿しており、こちらは今のところ無料機能の縮小はなさそうです。しかし、これを機に、PDFスライドを自サイト内で公開できるようにしたいなと思い、機能の検討と実装を行いました。
できたもの①
このように横スクロールでスライドを閲覧でき、スライド上のハイパーリンクをクリックできる(スライド2枚目参照)ようになっています。スライド単体のページ や スライド一覧 も参照してください。
本記事では、筆者が作成したPDFを自サイト内で公開する仕組みとスライドビューアーについて解説します。
できたもの②(デモレポジトリ)
honai/pdf-slide-viewer-generator
このサイトのソースコードは 公開 しているのでそちらを参考にしていただけるのですが、 実装の解説をしやすいようにデモレポジトリを作成しました。 デモレポジトリは、
- Fork または Use as template
- GitHub PagesとGitHub Actionsを有効にする
- PDFをアップロードする
の3ステップで簡単に個人用のスライド共有サイトができるようになっています! 自分用のこういうサイトが欲しい方はぜひ自由に使ってください(MITライセンスです)。
公開の手軽さを重視するためGitHub Pagesの仕組みに乗っかっており、 Jekyllを利用しています。 カルーセル自体やスライドの一覧にはスタイルを当てていますが、 それ以外はほぼスタイルを当てておらず素朴になっていますので、 各自で拡張していただければと思います。
本記事の解説内で、適宜デモレポジトリの該当実装部分へのリンクを貼っていますので、参考にしてください。 また、Jekyllに限らず、HugoやGatsbyなどの静的サイトジェネレータであれば、 紹介する仕組みを応用して同様のサイトを作成できると思います。
なぜスライドビューアーが必要なのか
SlideShareやSpeaker Deckなどのサービスでは、資料のPDFファイルをアップロードすることで、スライドショーのようなUIで資料を表示するWebページが生成されます。
しかし、そもそもPDFファイルは多くのブラウザで直接閲覧することができます。では、なぜPDFそのものではなく、HTMLや画像からなるページが必要なのでしょうか。
SEO
Googleなどの検索エンジンは、PDFファイルも内容を解析してインデックスすることができます。みなさんも、大学の講義資料や公的機関の資料などのPDFファイルに、検索エンジンで直接たどり着いて閲覧したことがあるのではないでしょうか。キーワードによっては、PDFファイルが検索上位に表示されることもよくあります。10年以上前の記事ですが、Googleからも以下のような記事が出ています。
検索結果における PDF ファイルの取り扱いについてのヒント | Google 検索セントラル ブログ | Google Developers
しかし、この記事からも読み取れるように、通常のHTMLによるWebサイトに比べてSEOの観点で以下のような欠点があります。
画像がインデックス登録されない
先ほどの記事によると
現時点では、PDF ファイル内の画像はインデックスには登録されません。画像をインデックス登録するには、その画像用の HTML ページを作成する必要があります。
とあります。テキストで検索はできますが、スライドが画像検索に表示されたほうが、資料を探しやすくなるでしょう。
PDFファイルによってはテキストが画像化されている
スライドを作成した後、PDFとして出力するときに、使用するアプリケーションや設定によっては、テキスト情報が失われてしまう場合もあります。先ほどの記事では
テキストが画像として埋め込まれている場合は、Google ではその画像を OCR (英語)アルゴリズムで処理し、テキストを抽出することができます。
とありますが、OCRの認識精度は100%ではないでしょう。スライドのタイトル、説明、中身をテキストとして提供できるほうが望ましいです。例えば、Speaker Deckでは、PDFをアップロードするときに、タイトルと説明を入力することができます。
ネットワークの転送量
ページ数が多かったり、埋め込まれている画像のサイズが大きかったりすると、当然PDFのファイルサイズは大きくなります。ブラウザでPDFを直接表示するときにはPDFファイル全体がダウンロードされるため、ファイルサイズが大きいと転送量が大きくなり、表示に時間がかかります。
HTMLと画像によるスライドビューアーなら、 画像の遅延読み込み などを使用することで、最初にスライドが表示されるまでの転送量を減らすことができます。
ユーザーインターフェース(UI)
SlideShareやSpeaker Deckなどのスライド共有サービスでは、スライドビューアーのページ内に、同じユーザーの他のスライドや関連するスライドなどが表示されます。 このように、スライドそのものだけでなく、関連コンテンツ・サイト内のナビゲーション・SNSシェアなどのUIをデバイスやブラウザによらず一貫して提供することは、PDFファイル単体では不可能です。
本節のまとめ
スライドをPDF形式でWebに公開することは、HTMLなどによるWebページ形式で公開する場合と比べて、SEO、ネットワーク転送量、UIなどにおいて欠点があります。
作成したスライドビューアーの要件
今回筆者がこのサイトにスライドビューアー(PDFを変換等する仕組みも含みます)を実装するにあたって、以下のような要件を考えました。
画像化されたスライドを、カルーセルとして表示できる
最も基本的な機能です。PDF形式のスライドの各ページを画像に変換し、カルーセルのUIとして表示します。
スライド上のリンクをクリックできる
Speaker DeckやSlideShareではスライドが画像化されるため、PDF上にあったURLリンクに直接ジャンプすることはできません[1]。 しかし、PDFを事前に解析すればリンクの情報を抽出できるはずです。 何らかの方法でリンクを抽出して、スライド画像上に表示できるようにします。
別のページにスライドを埋め込める
筆者はこれまで、Speaker Deckにアップロードしたスライドを自身のサイト内に埋め込んで利用していました。これと同様に、スライド単体のページだけでなく、別ページに埋め込む機能も実装します。 (デモレポジトリに関してはこの要件は省略されています。 理由は後述します。)
PDFをアップロードするだけでビューアーページが公開される
最後に自動化についての要件です。PDFを何らかの方法でアップロードすれば、あとは自動でそのスライドのWebページが公開されるようにします。
実装の解説(PDF解析・変換編)
まずはPDFを画像化したり、リンクやテキストを抽出する工程です。
画像化: Poppler
PDFの画像化は、Popplerというコマンドラインツールを使用しています。Popplerは、PDFを表示したり内容を解析・変更するためのソフトウェアで、GPLライセンスのOSSです。
Poppler: https://poppler.freedesktop.org/
PDFをPPM/PNG/JPEG等の画像形式に変換できる pdftoppm というコマンドを使用します。下記のように使用することができます。このコマンドには他にも数多くのオプションがあり、 pdftoppm --help で確認できます。
# Debian系なら以下でインストールできます
$ apt install poppler-utils
$ ls
example.pdf
$ pdftoppm -png example.pdf out
$ ls
exapmle.pdf out-01.png out-02.png out-03.png (略) out-10.png
リンクとテキストの抽出
PDF内のリンクやテキストの情報を抽出できるライブラリを探していると、Rubyのpdf-readerというライブラリを見つけました。
https://github.com/yob/pdf-reader
About欄によると、Adobe社によるPDFの仕様を可能な限り反映したPDFパーサーとのことです。 レポジトリ内に詳しいリファレンスはないので、詳細な仕様については、PDFの仕様そのものを当たる必要がありました。
PDFから抽出したい情報は主に
- 各ページのサイズ(幅、高さ)
- リンク(URLとページ内での位置)
- 各ページに含まれるテキスト
の3つです。
Rubyのサンプルコードを解説していきます。 まずはPDFを読み込み、メタ情報やテキスト、ページサイズの抽出をします。 以下のように簡単に行えます。
# Ruby
require "pdf-reader"
pdf_file = "./example.pdf"
reader = PDF::Reader.new(pdf_file)
p reader.pdf_version
# => 1.7
p reader.info
# => {
# :Title=>"タイトル",
# :Author=>"著者",
# :CreationDate=>"D:20220101000000+09'00'",
# :ModDate=>"D:20220102000000+09'00'"
# }
p reader.page_count
# => 10
p reader.pages
# => [<PDF::Reader::Page page: 1>, (略), <PDF::Reader::Page page: 10>]
p reader.pages[0].text
# => "タイトル 著者 フッター"
p [reader.pages[0].width, reader.pages[1].height] # ページの幅と高さ
# => [960, 540]
次はリンクの抽出です。 AdobeによるPDF 1.7の仕様 によると、 PDF内でURL(URI)にアクセスする機能は、”Interactive Features” の “URI Actions” (12.6.4.7,423ページ) として定義されています。 さらに、このActionをPDFのページ上の位置と紐付けるのが、同じく “Interactive Features” の “Link Annotations”(12.5.6.13,405ページ)です。[2]
あるページ上のリンクを抽出するコードは以下のようになります(上のコードからの続きとして読んでください)。
page = reader.pages[1]
links =
(page.attributes[:Annots] || []) # [:Annots]は仕様上optionalなのでnilの場合もある
.map do |ref_to_annotation|
# page.attributesに含まれるのは実際のannotation objectへの参照であるため、
# 参照先を見る
reader.objects[ref_to_annotation]
end
.filter do |annotation|
# URI Actionに対するLink Annotationだけを選択
annotation[:Subtype] == :Link && annotation[:A][:S] == :URI
end
.map do |annotation|
# Annotationの位置と、リンク先URLを抽出
{ rect: annotation[:Rect], url: annotation[:A][:URI] }
end
p links
# => [
# { rect: [123.86, 160.46, 232.22, 211.01], url: "https://example.com/" },
# { rect: [123.86, 110.9, 245.54, 161.42], url: "https://example.jp/" },
# ]
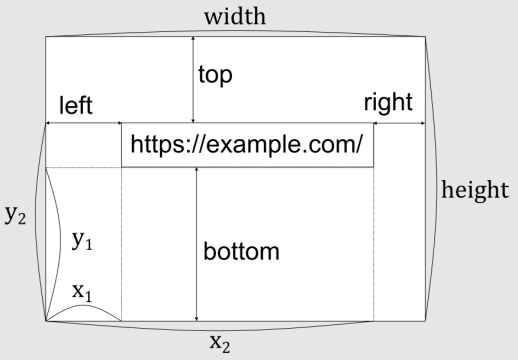
Rect は、4つの数からなる、Annotationの位置を示す値です[PDF1.7仕様 7.9.5 Rectangle(88ページ)参照]。
下図で表される から に対して、 [x_1, y_1, x_2, y_2] のように表されます。
原点が左下になっていることに注意してください。

このようにして、各ページのリンクの位置とリンク先を抽出することができます。後は、それらをJSON形式などで出力すれば良いでしょう。
デモレポジトリでは process-pdf.rb で実装されています。
自動化
4つ目の要件(PDFをアップロードするだけでビューアーページが公開される)を満たすため、画像化と情報の抽出をGitHub Actionsを使って自動化しました。
デモレポジトリでも、 assets/pdf ディレクトリ内にPDFを追加してPushすると、
GitHub ActionsのCI環境によって以下が行われます
- PopplerによってPDFの各ページの画像を生成
- PDFのタイトル・テキスト・リンクなどを抽出し、MarkdownファイルのFront matterとして[3]メタデータファイルを作成
- 生成されたMarkdownファイルと画像をレポジトリにコミット & プッシュ
詳しくは、デモレポジトリの GitHub Actions Workflowファイル を参照してください。 最後の、画像をレポジトリにコミットしている点について、このような構成にしたのは2つの理由があります。
- GitHub Pagesの仕組み上、公開したいファイルはコミットする必要がある。
- PDFが追加されたときにそのPDFに対してだけ画像化の処理をすれば済むようにするため
もちろん、クラウドストレージやSaaSを利用して画像はそちらにアップロードするという構成も可能でしょう。
実装の解説(UI編)
私はWebフロントエンドの分野が好きなので、今回特に楽しかったのはビューアーのUIを作る部分です。前章のPDFの解析・変換によって、PDFの各ページのメタデータと画像が得られました。これらをもとにカルーセルのインターフェースをHTML/CSS/JavaScriptで作っていきます。
CSSスクロールスナップ
CSS スクロールスナップ - CSS: カスケーディングスタイルシート | MDN
CSSスクロールスナップはCSSの機能の1つで、縦・横にスクロールする要素に対してスナップ点(スクロール終了の位置が吸い付く点)を導入することができます。この機能を用いると、CSSだけで、横にスクロールをすることでスライド画像に順にスナップされるようなカルーセルを実装することができます。 HTMLとCSSのベースは次のようになります。
<!-- HTML -->
<div class="carousel">
<div class="slide"><img src="slide-01.png" alt=""></div>
<div class="slide"><img src="slide-02.png" alt=""></div>
<div class="slide"><img src="slide-03.png" alt=""></div>
</div>
/* CSS */
.carousel {
width: 360px;
display: flex;
flex-flow: row nowrap;
overflow-x: scroll;
scroll-snap-type: x mandatory;
}
.carousel > .slide {
flex: 0 0 320px;
scroll-snap-align: center;
}
.slide > img {
width: 100%;
height: auto;
}
Can I use... によると、PC・モバイルともに主要ブラウザでサポートされています。
CSS Scroll Snap | Can I use...
リンクをクリックできるようにする
今回の個人的な推しポイントである、スライド中のリンクをクリックできる機能を実装します。ページの幅・高さとLink Annotationの位置をもとにリンクを描画します。
イメージマップ vs position: absolute
「画像上の特定の位置にハイパーリンクを設置する」という機能は、 <map> タグ や <area> タグ を利用したイメージマップで実現することができます。
しかし、位置を絶対座標で指定することしかできないため、デバイスの幅に合わせて画像のサイズが変わる場合、座標を書き換える必要があります。
PCやモバイルデバイスでの表示を考えると、スライドの画像サイズを固定するのは現実的ではありません。
せっかくカルーセルにCSSのみで実現できるスクロールスナップを採用したので、リンクの描画もJavaScriptを使わずにシンプルに実現したいと考えました。そこで、ナイーブですが、パーセントによって座標を相対指定できる position: absolute によって <a> タグを描画するのが良いと考え、こちらを採用しました。
RectangleからCSS位置指定への変換
先述したように、PDFから抽出したリンクの位置(Rectangle)は、長方形の各辺の位置を左下を原点とした座標で表したものなので、下図のように、RectangleからCSSのtop, left, bottom, rightのパーセント値に変換する必要があります。
// JavaScript
/**
* @param {number} rect [左端のx, 下端のy, 右端のx, 上端のy] すべて左下が原点
* @param {number} width PDFのページの幅
* @param {number} height PDFのページの高さ
*/
function rectToCssPosition(rect, width, height) {
const [left, bottom, right, top] = [
rect[0] / width,
rect[1] / height,
(width - rect[2]) / width,
(height - rect[3]) / height,
].map(ratio => `${(ratio * 100).toFixed(2)}%`)
return { left, bottom, right, top }
}
console.log(rectToCssPosition([10, 10, 300, 50], 400, 300))
// { left: '2.50%', bottom: '3.33%', right: '25.00%', top: '83.33%' }
(デモレポジトリでは Rubyの変換スクリプト内で実装 しています。) これを使って以下のようにHTMLを生成します。
// JSX
const SlidePageWithLinks = ({ src, width, height, links }) => {
return (
<div class="slide">
<img src={src} alt="" width={width} height={height} />
{links.map(({ rect, url }) => (
<a
href={url}
title={url}
style={rectToCssPosition(rect, width, height)}
/>
))}
</div>
);
};
const links = [
{ rect: [(略)], url: "https://example.com/" },
{ rect: [(略)], url: "https://example.jp/" },
];
const html = renderToStaticMarkup(
<SlidePageWithLinks
src="slide.png"
width={800}
height={600}
links={links}
/>
);
console.log(html);
// <div class="slide">
// <img src="slide.png" alt="" width="800" heigth="600">
// <a href="http://(略)"
// style="top:XX%; left:XX%; right: XX%; bottom: XX%;"
// ></a>w
// <a href="http://(略)" (...略)></a>
// ...
// </div>
このように生成したHTMLは、以下のようなスタイルを当てることで、親要素の幅に追従するリンク付きの画像が完成します。
.slide {
position: relative;
}
.slide > img {
width: 100%;
height: auto;
}
.slide > a {
position: absolute;
border: 2px dashed blue;
}
デモ (“Resize me” の場所にあるハンドルで、画像の幅が親要素に追従することを確かめてみてください)
カルーセルとイメージマップを合わせたデモ も参照してください。
カルーセルは、デモレポジトリでは、 このファイル と SCSSファイルたち によって実装がなされています。
スライドカルーセルを便利にするUIの追加実装
本節では筆者がカルーセルに実装したUIについて簡単に解説します。
ボタンでのスライド切り替え
スクロールスナップを mandatory にしていても、1回の操作で、2スナップ分スクロールされる場合があります。
特にモバイルデバイスのスワイプ操作でスクロールするときにこうなることが多く、
1スライドずつ閲覧したいときに不便です。
そこで、 <button> 要素に
カルーセルを1スライド分スクロールするイベントハンドラを設定することで、
ボタンによるスライド切り替えを実現しています。
デモレポジトリでの実装は以下のリンク先をご覧ください。
キーボードでのスライド切り替え
さらに、一般的なスライドショーアプリのように、 キーボードの左右キーでスライドを切り替えられたほうが便利です。 そこで、カルーセルのコントロールにフォーカスがあるときにキーボードイベントを補足して、 左右矢印キーのときはスライドを送ったり戻したりするようにしました。 デモレポジトリでの実装は このあたり です。
スライダーでのスライド切り替え

カルーセルをCSSスクロールスナップで実装すると、 PCブラウザではスクロールバーをドラッグして素早くスクロールできますが、 スクロールバーを直接操作できないモバイルブラウザでは不便です (iOS版Safariではスクロールバーを直接スライドできるようです)。
そこで、スクロールバーの代わりに、モバイルブラウザでもスライド操作でページを切り替えられるUIを実装しました。
パーツとしては、ブラウザ標準の <input type="range"> 要素を使いました。
筆者のサイトのスライドビューアーでは、
画像SaaSと組み合わせることで、スライダーをドラッグ中にサムネイルを表示するようにしていますが、
デモレポジトリではサムネイル表示は省略しています。
デモレポジトリでの実装は このあたり です。 筆者のサイトでの実装は このファイル を参考にしてください。
iframeによる埋め込みページの作成
要件「別のページにスライドを埋め込める」を実現するために、iframeでの埋め込み用ページを作成しました。 といっても、基本的には前節で説明したカルーセルをビューポートいっぱいに表示するようなページを作成するだけです。 iframeの埋め込みコードに、 CSSのaspect-ratio による縦横比指定を入れておくと、スライドの縦横比に合わせた埋め込み要素を作成できます。
デモレポジトリではJekyllを使っていて、Jekyllでは「1つのデータから複数のHTMLページを出力する」ことがプラグインなしではできなかったので、省略しています。 Hugoは “Custom Output Formats” にてHTML形式の新しいフォーマットを定義すれば可能です。 筆者のサイトで使っているEleventyでは “Create pages from data” のコンセプトを利用すれば可能です。
TwitterのPlayer Cardでツイートにスライドを埋め込む
これはおまけなのですが、TwitterのPlayer Cardを利用すれば、 ブラウザ版のTwitterやTweetdeckでツイート内にスライドビューアーを埋め込んで表示することができます。 SlideShareがこのようなPlayer Cardに対応していたので、筆者もやってみました。
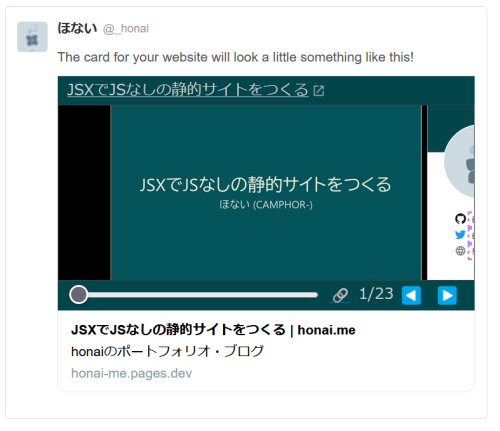
対応は簡単で、 Player Cardのドキュメント に従って、 スライドページのHTMLに以下のようなmetaタグを指定します。
<meta name="twitter:card" content="player"><meta name="twitter:player" content="{埋め込みURL}">
他の twitter:title などのmetaタグが必要なのは通常の(サムネイル画像を表示させる)Twitter Cardと同じです。
まとめ・感想
この記事では、筆者が自身のサイト内で自身のスライドを公開・共有できるようにした仕組み・実装について解説しました。 なぜPDFそのものではなくスライドビューアーサイトが必要なのかについて述べた後、 機能の要件、そして実装方法をデモコードとともに解説しました。 PDFの仕様にも片足を突っ込んだりして、勉強になりました
既存のスライド共有サービスと同じような機能を実現しつつ、リンクのクリックなど追加機能も実装して、楽しく取り組めました。
みなさんも自分のスライド共有サイトを作ってみてください。 読んでいただきありがとうございました。